
作者: afenxi来源: afenxi时间:2017-01-16 09:31:51
摘要:K临近分类算法是数据挖掘中较为简单的一种分类方法,通过计算不同数据点间的距离对数据进行分类,并对新的数据进行分类预测。
K临近分类算法是数据挖掘中较为简单的一种分类方法,通过计算不同数据点间的距离对数据进行分类,并对新的数据进行分类预测。我们在之前的文章《K邻近(KNN)分类和预测算法的原理及实现》和《协同过滤推荐算法的原理及实现》两篇文章中都详细介绍过。本篇文章将介绍在python中使用机器学习库sklearn建立K临近模型(k-NearestNeighbor)的过程并使用模型对数据进行预测。
 准备工作
准备工作
首先是开始前的准备工作,导入我们需要使用的库文件。这里一共需要使用5个库文件。第一个是机器学习库,第二个是用于模型检验的交叉检验库,第三个是数值计算库,第四个是科学计算库,最后是图表库。
1 2 3 4 5 6 7 8 9 10 #导入机器学习KNN分析库 from sklearn.neighbors import KNeighborsClassifier #导入交叉验证库 from sklearn import cross_validation #导入数值计算库 import numpy as np #导入科学计算库 import pandas as pd #导入图表库 import matplotlib.pyplot as plt 读取并查看数据表
读取并导入所需数据,创建名为knn_data的数据表,后面我们将使用这个数据对模型进行训练和检验。
1 2 #读取并创建名为knn_data的数据表 knn_data=pd.DataFrame(pd.read_csv(knn_data.csv))
使用head函数查看数据表的内容,这里只查看前5行的数据,数据表中包含三个字段,分别为贷款金额,用户收入和贷款状态。我们希望通过贷款金额和用户收入对最终的贷款状态进行分类和预测。
1 2 #查看数据表前5行 knn_data.head(5)  绘制散点图观察分类
绘制散点图观察分类
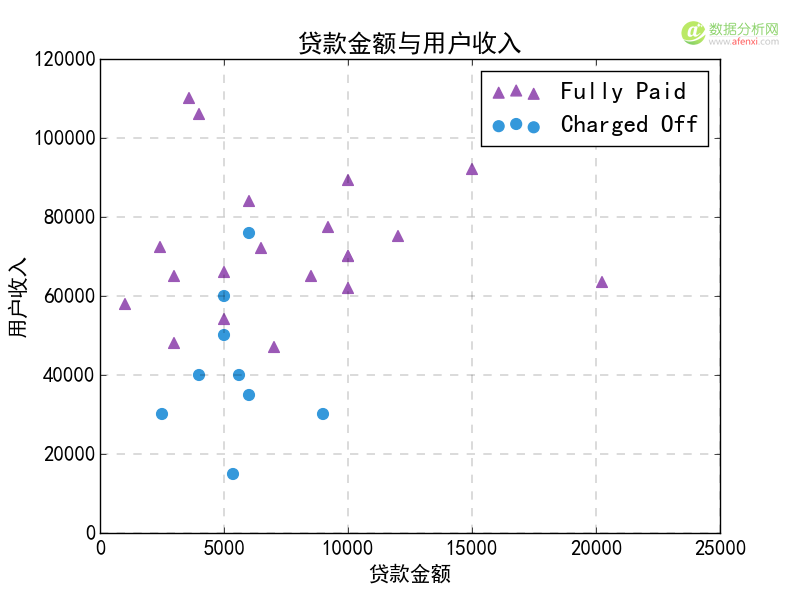
创建模型之前先对数据汇总散点图,观察贷款金额和用户收入两个变量的关系以及对贷款状态的影响,下面是具体的代码,根据贷款状态将数据分为两组,第一组为Fully Paid,第二组为Charged Off。
1 2 3 4 5 6 7 8 #Fully Paid数据集的x1 fully_paid_loan=knn_data.loc[(knn_data["loan_status"] == "Fully Paid"),["loan_amnt"]] #Fully Paid数据集的y1 fully_paid_annual=knn_data.loc[(knn_data["loan_status"] == "Fully Paid"),["annual_inc"]] #Charge Off数据集的x2 charged_off_loan=knn_data.loc[(knn_data["loan_status"] == "Charged Off"),["loan_amnt"]] #Charge Off数据集的y2 charged_off_annual=knn_data.loc[(knn_data["loan_status"] == "Charged Off"),["annual_inc"]]
数据分组后开始绘制散点图,下面是绘图过程和具体的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #设置图表字体为华文细黑,字号15 plt.rc(font, family=STXihei, size=15) #绘制散点图,Fully Paid数据集贷款金额x1,用户年收入y1,设置颜色,标记点样式和透明度等参数 plt.scatter(fully_paid_loan,fully_paid_annual,color=#9b59b6,marker=^,s=60) #绘制散点图,Charge Off数据集贷款金额x2,用户年收入y2,设置颜色,标记点样式和透明度等参数 plt.scatter(charged_off_loan,charged_off_annual,color=#3498db,marker=o,s=60) #添加图例,显示位置右上角 plt.legend([Fully Paid, Charged Off], loc=upper right) #添加x轴标题 plt.xlabel(贷款金额) #添加y轴标题 plt.ylabel(用户收入) #添加图表标题 plt.title(贷款金额与用户收入) #设置背景网格线颜色,样式,尺寸和透明度 plt.grid( linestyle=--, linewidth=0.2) #显示图表 plt.show()
在散点图中,紫色三角形为Fully Paid组,蓝色圆形为Charged Off组。我们所要做的是通过KNN模型对这两组数据的特征进行学习,例如从肉眼来看Fully Paid组用户收入要高于Charged Off组。并使用模型对新的数据进行分类预测。
 设置模型的自变量和因变量
设置模型的自变量和因变量
创建KNN模型前,先设置模型中的自变量和因变量,也就是特征和分类。这里将贷款金额和用户收入设置为自变量,贷款状态是我们希望预测的结果,因此设置为因变量。
1 2 3 4 #将贷款金额和用户收入设为自变量X X = np.array(knn_data[[loan_amnt,annual_inc]]) #将贷款状态设为因变量Y Y = np.array(knn_data[loan_status])
设置完成后查看自变量和因变量的行数,这类一共有29行数据,后面我们将把这29行数据分割为训练集和测试集,训练集用来建立模型,测试集则对模型的准确率进行检验。
1 2 #查看自变量和因变量的行数 X.shape,Y.shape ![]() 将数据分割为训练集和测试集
将数据分割为训练集和测试集
采用随机抽样的方式将数据表分割为训练集和测试集,其中60%的训练集数据用来训练模型,40%的测试集数据用来检验模型准确率。
1 2 #将原始数据通过随机方式分割为训练集和测试集,其中测试集占比为40% X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, Y, test_size=0.4, random_state=0)
分割后测试集的数据为17条。这些数据用来训练模型。
1 2 #查看训练集数据的行数 X_train.shape,y_train.shape ![]() 对模型进行训练
对模型进行训练
将训练集数据X_train和y_train代入到KNN模型中,对模型进行训练。下面是具体的代码和结果。
1 2 3 #将训练集代入到KNN模型中 clf = KNeighborsClassifier(n_neighbors=3) clf.fit(X_train,y_train)  使用测试集测对模型进行测试
使用测试集测对模型进行测试
使用测试集数据X_test和y_test对训练后的模型进行检验,模型准确率为75%。
1 2 #使用测试集衡量模型准确度 clf.score(X_test, y_test) ![]()
完成训练和测试后,使用模型对新数据进行分类和预测,下面我们建立一组新的数据,贷款金额为5000元,用户收入为40000,看看模型对新数据的分组结果。
1 2 #设置新数据,贷款金额5000,用户收入40000 new_data = np.array([[5000,40000]])
模型对新数据的分组结果为Charged Off。这个分类准确吗?我们继续再来看下模型对这组新数据分组的概率。
1 2 #对新数据进行分类预测 clf.predict(new_data) ![]()
67%的概率为Charged Off,33%的概率为Fully Paid。根据这一概率模型将新数据划分到Charged Off组。
1 2 #新数据属于每一个分类的概率 clf.classes_,clf.predict_proba(new_data) 



