
作者: afenxi来源: afenxi时间:2017-03-10 17:53:01
摘要:编码问题是编程过程中最常遇见的问题之一,本文清晰地介绍了计算机编码的由来,以及如何处理乱码等技巧。
这是我在知乎上回答的一个问题:Python 编码为什么那么蛋疼?(https://www.zhihu.com/question/31833164),期间收到了不少赞,不过发现我的回答还存在一些误导,于是通过查找资料重新整理了一篇,希望能解答你对编码的困惑。
一旦走上了编程之路,如果你不把编码问题搞清楚,那么它将像幽灵一般纠缠你整个职业生涯,各种灵异事件会接踵而来,挥之不去。只有充分发挥程序员死磕到底的精神你才有可能彻底摆脱编码问题带来的烦恼,我第一次遇到编码问题是写 JavaWeb 相关的项目,一串字符从浏览器游离到应用程序代码中,翻江倒海沉浸到数据库中,随时随地都有可能踩到编码的地雷。第二次遇到编码问题就是学 Python 的时候,在爬取网页数据时,编码问题又出现了,当时我的心情是奔溃的,用时下最ing的一句话就是:“我当时就懵逼了”。为了搞清字符编码,我们得从计算机的起源开始,计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的数字形式存储的。我们是幸运的,我们也是不幸的,幸运的是时代赋予了我们都有机会接触计算机,不幸的是,计算机不是我们国人发明的,所以计算机的标准得按美帝国人的习惯来设计,那么最开始计算机是通过什么样的方式来表现字符的呢?这要从计算机编码的发展史说起。
ASCII
每个做 JavaWeb 开发的新手都会遇到乱码问题,每个做 Python 爬虫的新手都会遇到编码问题,为什么编码问题那么蛋疼呢?这个问题要从1992年 Guido van Rossum 创造 Python 这门语言说起,那时的 Guido 绝对没想到的是 Python 这门语言在今天会如此受大家欢迎,也不会想到计算机发展速度会如此惊人,尽管 Guido 在当初设计这门语言时是不需要关心编码的,因为在英语世界里,字符的个数非常有限,26个字母(大小写)、10个数字、标点符号、控制符,也就是键盘上所有的键所对应的字符加起来也不过是一百多个字符而已,这在计算机中用一个字节的存储空间来表示一个字符是绰绰有余的,因为一个字节相当于8个比特位,8个比特位可以表示256个符号。于是聪明的美国人就制定了一套字符编码的标准叫ASCII(American Standard Code for Information Interchange),每个字符都对应唯一的一个数字,比如字符A对应的二进制数值是01000001,对应的十进制就是65。最开始ASCII只定义了128个字符编码,包括96个文字和32个控制符号,一共128个字符只需要一个字节的7位就能表示所有的字符,因此 ASCII 只使用了一个字节的后7位,最高位都为0。每个字符与ASCII码的对应关系可查看网站ascii-code。
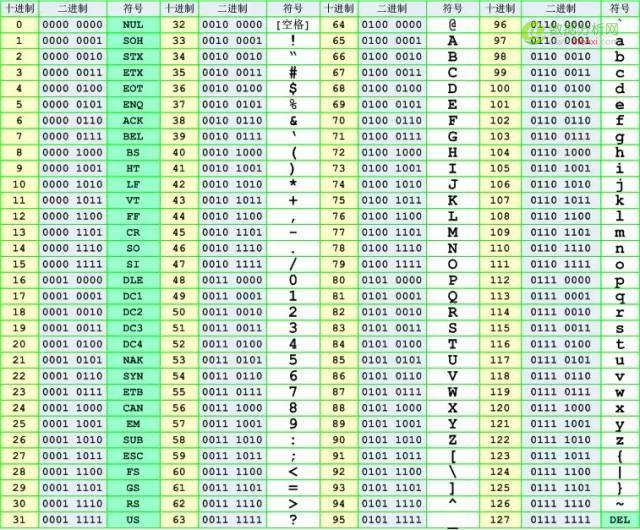
EASCII(ISO/8859-1)
然而计算机慢慢地普及到其他西欧地区时,他们发现还有很多西欧所特有的字符是 ASCII 编码表中没有的,于是后来出现了可扩展的 ASCII 叫 EASCII ,顾名思义,它是在ASCII的基础上扩展而来,把原来的7位扩充到8位,它完全兼容ASCII,扩展出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。然而 EASCII 时代是一个混乱的时代,大家没有统一标准,他们各自把最高位按照自己的标准实现了自己的一套字符编码标准,比较著名的就有 CP437, CP437 是 Windows 系统中使用的字符编码,如下图:
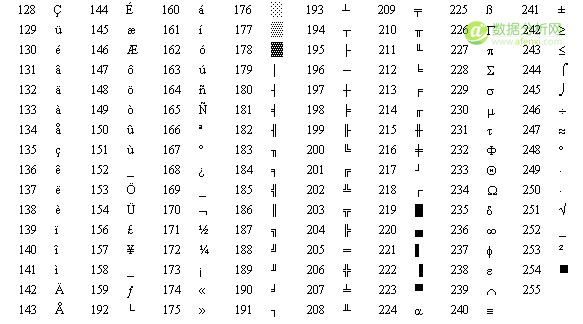
另外一种被广泛使用的 EASCII 还有 ISO/8859-1(Latin-1),它是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位元字符集的标准,ISO/8859-1 只继承了 CP437 字符编码的128-159之间的字符,所以它是从160开始定义的,不幸的是这些众多的 ASCII 扩充字集之间互不兼容。

GBK
随着时代的进步,计算机开始普及到千家万户,比尔盖茨让每个人桌面都有一台电脑的梦想得以实现。但是计算机进入中国不得不面临的一个问题就是字符编码,虽然咱们国家的汉字是人类使用频率最多的文字,汉字博大精深,常见的汉字就有成千上万,这已经大大超出了 ASCII 编码所能表示的字符范围了,即使是 EASCII 也显得杯水车薪,于是聪明的中国人自己弄了一套编码叫 GB2312,又称GB0,1981由中国国家标准总局发布。GB2312 编码共收录了6763个汉字,同时他还兼容 ASCII,GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率,不过 GB2312 还是不能100%满足中国汉字的需求,对一些罕见的字和繁体字 GB2312 没法处理,后来就在GB2312的基础上创建了一种叫 GBK 的编码,GBK 不仅收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。同样 GBK 也是兼容 ASCII 编码的,对于英文字符用1个字节来表示,汉字用两个字节来标识。
Unicode
对于如何处理中国人自己的文字我们可以另立山头,按照我们自己的需求制定一套编码规范,但是计算机不止是美国人和中国人用啊,还有欧洲、亚洲其他国家的文字诸如日文、韩文全世界各地的文字加起来估计也有好几十万,这已经大大超出了ASCII码甚至GBK所能表示的范围了,况且人家为什么用采用你GBK标准呢?如此庞大的字符库究竟用什么方式来表示好呢?于是统一联盟国际组织提出了Unicode编码,Unicode的学名是”Universal Multiple-Octet Coded Character Set”,简称为UCS。Unicode有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,一共16个比特位,这样理论上最多可以表示65536个字符,不过要表示全世界所有的字符显示65536个数字还远远不过,因为光汉字就有近10万个,因此Unicode4.0规范定义了一组附加的字符编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)。理论上完全可以涵盖一切语言所用的符号。世界上任何一个字符都可以用一个Unicode编码来表示,一旦字符的Unicode编码确定下来后,就不会再改变了。但是Unicode有一定的局限性,一个Unicode字符在网络上传输或者最终存储起来的时候,并不见得每个字符都需要两个字节,比如一字符“A“,用一个字节就可以表示的字符,偏偏还要用两个字节,显然太浪费空间了。第二问题是,一个Unicode字符保存到计算机里面时就是一串01数字,那么计算机怎么知道一个2字节的Unicode字符是表示一个2字节的字符呢,还是表示两个1字节的字符呢,如果你不事先告诉计算机,那么计算机也会懵逼了。Unicode只是规定如何编码,并没有规定如何传输、保存这个编码。例如“汉”字的Unicode编码是6C49,我可以用4个ascii数字来传输、保存这个编码;也可以用utf-8编码的3个连续的字节E6 B1 89来表示它。关键在于通信双方都要认可。因此Unicode编码有不同的实现方式,比如:UTF-8、UTF-16等等。这里的Unicode就像英语一样,做为国与国之间交流世界通用的标准,每个国家有自己的语言,他们把标准的英文文档翻译成自己国家的文字,这是实现方式,就像utf-8。
UTF-8
UTF-8(Unicode Transformation Format)作为Unicode的一种实现方式,广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。比如英文字符这些原本就可以用ASCII码表示的字符用UTF-8表示时就只需要一个字节的空间,和ASCII是一样的。对于多字节(n个字节)的字符,第一个字节的前n为都设为1,第n+1位设为0,后面字节的前两位都设为10。剩下的二进制位全部用该字符的unicode码填充。
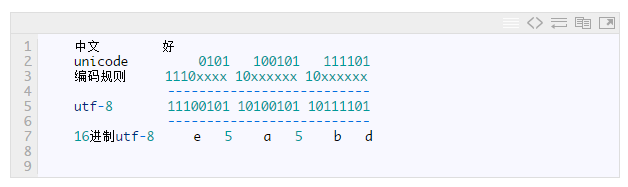
以汉字“好”为例,“好”对应的Unicode是597D,对应的区间是0000 0800–0000 FFFF,因此它用UTF-8表示时需要用3个字节来存储,597D用二进制表示是: 0101100101111101,填充到1110xxxx 10xxxxxx 10xxxxxx得到11100101 10100101 10111101,转换成16进制:e5a5bd,因此“好”的Unicode”597D”对应的UTF-8编码是”E5A5BD”
PYTHON字符编码
现在总算把理论说完了。再来说说Python中的编码问题。Python的诞生时间比Unicode要早很多,Python的默认编码是ASCII
>>> import sys
>>> sys.getdefaultencoding()
ascii
所以在Python源代码文件中如果不显示地指定编码的话,将出现语法错误
#test.py
print "你好"
上面是test.py脚本,运行 python test.py 就会包如下错误:
File “test.py”, line 1 yntaxError: Non-ASCII character ‘xe4′ in file test.py on line 1, but no encoding declared; see http://www.python.org/ ps/pep-0263.html for details
为了在源代码中支持非ASCII字符,必须在源文件的第一行或者第二行显示地指定编码格式:
# coding=utf-8
或者是:
#!/usr/bin/python
# -*- coding: utf-8 -*-
在python中和字符串相关的数据类型,分别是str、unicode两种,他们都是basestring的子类,可见str与unicode是两种不同类型的字符串对象。
basestring
/
/
str unicode
对于同一个汉字“好”,用str表示时,它对应的就是utf-8编码的’xe5xa5xbd’,而用unicode表示时,他对应的符号就是u’u597d’,与u"好"是等同的。需要补充一点的是,str类型的字符其具体的编码格式是UTF-8还是GBK,还是其他格式,根据操作系统相关。比如在Windows系统中,cmd命令行中显示的:
# windows终端
>>> a = 好
>>> type(a)
<type str>
>>> a
xbaxc3
而在Linux系统的命令行中显示的是:
# linux终端
>>> a=好
>>> type(a)
<type str>
>>> a
xe5xa5xbd
>>> b=u好
>>> type(b)
<type unicode>
>>> b
uu597d
不论是Python3x、Java还是其他编程语言,Unicode编码都成为语言的默认编码格式,而数据最后保存到介质中的时候,不同的介质可有用不同的方式,有些人喜欢用UTF-8,有些人喜欢用GBK,这都无所谓,只要平台统一的编码规范,具体怎么实现并不关心。
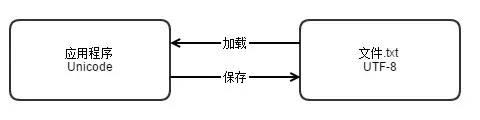
str与unicode的转换
那么在Python中str和unicode之间是如何转换的呢?这两种类型的字符串类型之间的转换就是靠这两个方法decode和encode。
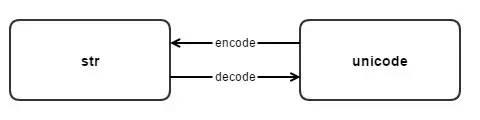
#从str类型转换到unicode
s.decode(encoding) =====> <type str> to <type unicode>
#从unicode转换到str
u.encode(encoding) =====> <type unicode> to <type str>
>>> c = b.encode(utf-8)
>>> type(c)
<type str>
>>> c
xe5xa5xbd
>>> d = c.decode(utf-8)
>>> type(d)
<type unicode>
>>> d
uu597d
这个’xe5xa5xbd’就是unicode u’好’通过函数encode编码得到的UTF-8编码的str类型的字符串。反之亦然,str类型的c通过函数decode解码成unicode字符串d。
str(s)与unicode(s)
str(s)和unicode(s)是两个工厂方法,分别返回str字符串对象和unicode字符串对象,str(s)是s.encode(‘ascii’)的简写。实验:
>>> s3 = u"你好"
>>> s3
uu4f60u597d
>>> str(s3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: ascii codec cant encode characters in position 0-1: ordinal not in range(128)
上面s3是unicode类型的字符串,str(s3)相当于是执行s3.encode(‘ascii’)因为“你好”两个汉字不能用ascii码来表示,所以就报错了,指定正确的编码:s3.encode(‘gbk’)或者s3.encode(“utf-8”)就不会出现这个问题了。类似的unicode有同样的错误:
>>> s4 = "你好"
>>> unicode(s4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: ascii codec cant decode byte 0xc4 in position 0: ordinal not in range(128)
>>>
unicode(s4)等效于s4.decode(‘ascii’),因此要正确的转换就要正确指定其编码s4.decode(‘gbk’)或者s4.decode(“utf-8”)。
乱码
所有出现乱码的原因都可以归结为字符经过不同编码解码在编码的过程中使用的编码格式不一致,比如:
# encoding: utf-8
>>> a=好
>>> a
xe5xa5xbd
>>> b=a.decode("utf-8")
>>> b
uu597d
>>> c=b.encode("gbk")
>>> c
xbaxc3
>>> print c
��
utf-8编码的字符‘好’占用3个字节,解码成Unicode后,如果再用gbk来解码后,只有2个字节的长度了,最后出现了乱码的问题,因此防止乱码的最好方式就是始终坚持使用同一种编码格式对字符进行编码和解码操作。

其他技巧
对于如unicode形式的字符串(str类型):
s = idu003d215903184u0026indexu003d0u0026stu003d52u0026sid’
转换成真正的unicode需要使用:
s.decode(unicode-escape)
测试:
>>> s = idu003d215903184u0026indexu003d0u0026stu003d52u0026sidu003d95000u0026i
>>> print(type(s))
<type str>
>>> s = s.decode(unicode-escape)
>>> s
uid=215903184&index=0&st=52&sid=95000&i
>>> print(type(s))
<type unicode>
>>>
以上代码和概念都是基于Python2.x。
参考:
https://www.python.org/dev/peps/pep-0263/ http://www.liaoxuefengcom/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386819196283586a37629844456ca7e5a7faa9b94ee8000 http://www.fmddlmyy.cn/text6.html
来源:http://foofish.net/blog/111/python-character-encode
本文作者:lzjun567(刘志军),程序员一枚,关注 Java、Python、云计算,移动互联网。(新浪微博:@_Zhijun)



