
作者: afenxi来源: afenxi时间:2017-05-20 19:43:18
摘要:如何使用逻辑回归模型预测股票涨跌
导读:逻辑回归是一个分类器,其基本思想可以概括为:对于一个二分类(0~1)问题,若P(Y=1/X)>0.5则归为1类,若P(Y=1/X)<0.5,则归为0类。
一、模型概述
1、Sigmoid函数
为了具象化前文的基本思想,这里介绍Sigmoid函数:
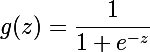
函数图像如下:
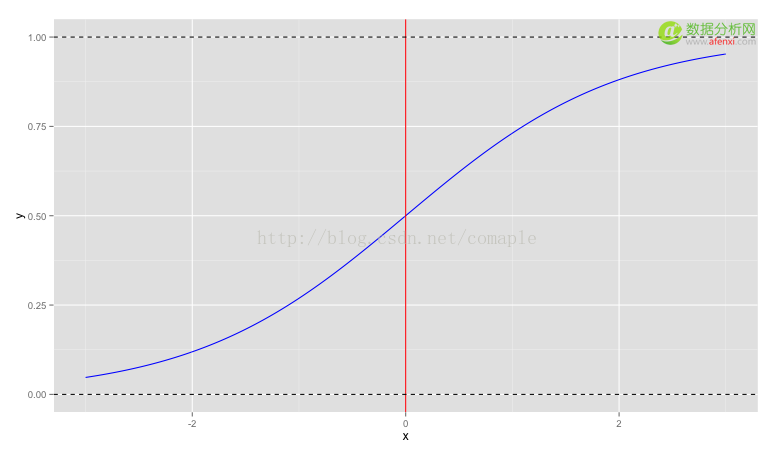
红色的线条,即x=0处将Sigmoid曲线分成了两部分:当 x < 0,y < 0.5 ; 当x > 0时,y > 0.5 。
实际分类问题中,往往根据多个预测变量来对响应变量进行分类。因此Sigmoid函数要与一个多元线性函数进行复合,才能应用于逻辑回归。
2、逻辑斯谛模型 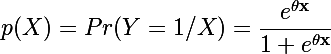
其中θx=θ1x1+θ2x2+……+θnxn 是一个多元线性模型。
上式可转化为:
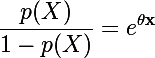
公式左侧称为发生比(odd)。当p(X)接近于0时,发生比就趋近于0;当p(X)接近于1时,发生比就趋近于∞。
两边取对数有:
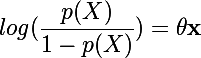
公式左侧称为对数发生比(log-odd)或分对数(logit),上式就变成了一个线性模型。
不过相对于最小二乘拟合,极大似然法有更好的统计性质。逻辑回归一般用极大似然法来拟合,拟合过程这里略过,下面只介绍如何用R应用逻辑回归算法。
二、逻辑回归应用 1、数据集
应用ISLR包里的Smarket数据集。先来看一下数据集的结构:
> summary(Smarket) Year Lag1 Lag2 Min. :2001 Min. :-4.922000 Min. :-4.922000 1st Qu.:2002 1st Qu.:-0.639500 1st Qu.:-0.639500 Median :2003 Median : 0.039000 Median : 0.039000 Mean :2003 Mean : 0.003834 Mean : 0.003919 3rd Qu.:2004 3rd Qu.: 0.596750 3rd Qu.: 0.596750 Max. :2005 Max. : 5.733000 Max. : 5.733000 Lag3 Lag4 Lag5 Min. :-4.922000 Min. :-4.922000 Min. :-4.92200 1st Qu.:-0.640000 1st Qu.:-0.640000 1st Qu.:-0.64000 Median : 0.038500 Median : 0.038500 Median : 0.03850 Mean : 0.001716 Mean : 0.001636 Mean : 0.00561 3rd Qu.: 0.596750 3rd Qu.: 0.596750 3rd Qu.: 0.59700 Max. : 5.733000 Max. : 5.733000 Max. : 5.73300 Volume Today Direction Min. :0.3561 Min. :-4.922000 Down:602 1st Qu.:1.2574 1st Qu.:-0.639500 Up :648 Median :1.4229 Median : 0.038500 Mean :1.4783 Mean : 0.003138 3rd Qu.:1.6417 3rd Qu.: 0.596750 Max. :3.1525 Max. : 5.733000
Smarket是2001年到2005年间1250天的股票投资回报率数据,Year是年份,Lag1~Lag5分别指过去5个交易日的投资回报率,Today是今日投资回报率,Direction是市场走势,或Up(涨)或Down(跌)。
library(corrplot) corrplot(corr = cor(Smarket[,-9]),order = "AOE",type = "upper",tl.pos = "d") corrplot(corr = cor(Smarket[,-9]),add=TRUE,type = "lower",method = "number",order = "AOE",diag = FALSE,tl.pos = "n",cl.pos = "n")
先看一下各变量的相关系数:
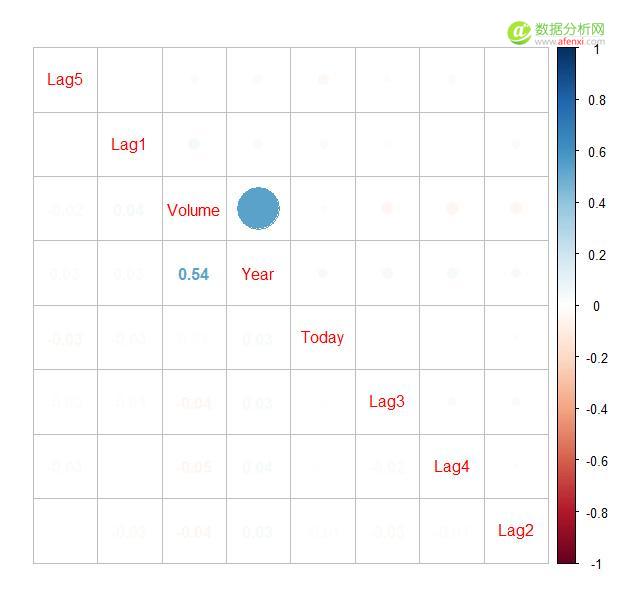
可见除了Volume和Year之间相关系数比较大,说明交易量基本随年份在增长,其他变量间基本没多大的相关性。说明股票的历史数据与未来的数据相关性很小,利用监督式学习方法很难准确预测未来股市的情况,这也是符合常识的。不过作为算法的应用教程,我们还是试一下。
2、训练并测试逻辑回归模型
逻辑回归模型是广义线性回归模型的一种,因此函数是glm(),但必须加上参数family=binomial。
> attach(Smarket) > # 2005年前的数据用作训练集,2005年的数据用作测试集 > train = Year<2005 > # 对训练集构建逻辑斯谛模型 > glm.fit=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume, + data=Smarket,family=binomial, subset=train) > # 对训练好的模型在测试集中进行预测,type="response"表示只返回概率值 > glm.probs=predict(glm.fit,newdata=Smarket[!train,],type="response") > # 根据概率值进行涨跌分类 > glm.pred=ifelse(glm.probs >0.5,"Up","Down") > # 2005年实际的涨跌状况 > Direction.2005=Smarket$Direction[!train] > # 预测值和实际值作对比 > table(glm.pred,Direction.2005) Direction.2005 glm.pred Down Up Down 77 97 Up 34 44 > # 求预测的准确率 > mean(glm.pred==Direction.2005) [1] 0.4801587
预测准确率只有0.48,还不如瞎猜。下面尝试着调整模型。
#检查一下模型概况 > summary(glm.fit) Call: glm(formula = Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 + Volume, family = binomial, data = Smarket, subset = train) Deviance Residuals: Min 1Q Median 3Q Max -1.302 -1.190 1.079 1.160 1.350 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 0.191213 0.333690 0.573 0.567 Lag1 -0.054178 0.051785 -1.046 0.295 Lag2 -0.045805 0.051797 -0.884 0.377 Lag3 0.007200 0.051644 0.139 0.889 Lag4 0.006441 0.051706 0.125 0.901 Lag5 -0.004223 0.051138 -0.083 0.934 Volume -0.116257 0.239618 -0.485 0.628 (Dispersion parameter for binomial family taken to be 1) Null deviance: 1383.3 on 997 degrees of freedom Residual deviance: 1381.1 on 991 degrees of freedom AIC: 1395.1 Number of Fisher Scoring iterations: 3
可以发现所有变量的p值都比较大,都不显著。前面线性回归章节中提到AIC越小,模型越优,这里的AIC还是比较大的。
加入与响应变量无关的预测变量会造成测试错误率的增大(因为这样的预测变量会增大模型方差,但不会相应地降低模型偏差),所以去除这样的预测变量可能会优化模型。
上面模型中Lag1和Lag2的p值明显比其他变量要小,因此只选这两个变量再次进行训练。
> glm.fit=glm(Direction~Lag1+Lag2, + data=Smarket,family=binomial, subset=train) > glm.probs=predict(glm.fit,newdata=Smarket[!train,],type="response") > glm.pred=ifelse(glm.probs >0.5,"Up","Down") > table(glm.pred,Direction.2005) Direction.2005 glm.pred Down Up Down 35 35 Up 76 106 > mean(glm.pred==Direction.2005) [1] 0.5595238 > 106/(76+106) [1] 0.5824176
这次模型的总体准确率达到了56%,总算说明统计模型的预测准确度比瞎猜要好(虽然只有一点点)。根据混淆矩阵,当逻辑回归模型预测下跌时,有50%的准确率;当逻辑回归模型预测上涨时,有58%的准确率。(矩阵的行名表预测值,列名表实际值)
应用这个模型来预测2组新的数据:
> predict(glm.fit,newdata = data.frame(Lag1=c(1.2,1.5),Lag2=c(1.1,-0.8)),type="response") 1 2 0.4791462 0.4960939
可见对于(Lag1,Lag2)=(1.2,1.1)和(1.5,-0.8)这两点来说,模型预测的都是股票会跌。需要注意的是,逻辑回归的预测结果并不能像线性回归一样提供置信区间(或预测区间),因此加上interval参数也没用。
参考文献
[1] R语言数据分析系列之九 - 逻辑回归 [2] Gareth James et al. An Introduction to Statistical Learning.
来源:数据人网
链接:http://shujuren.org/article/159.html



