
作者: afenxi来源: afenxi时间:2017-05-25 14:51:27
本人刚刚完成SAS正则表达式的学习,初学SAS网络爬虫,看到过一些前辈大牛们爬虫程序,感觉很有趣。现在结合实际例子,浅谈一下怎么做一些最基本的网页数据抓取。第一次发帖,不妥之处,还望各位大牛们指正。
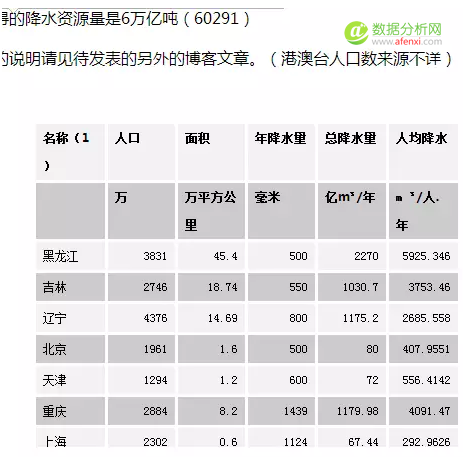
本帖研究网页为http://health.gmw.cn/2012-10/03/content_5266132.htm,意在提取该网页中全国各省降雨量信息,部分截图如下:
 大致步骤就是用filename fileref url 网页地址获取网页代码信息(包含有待提取数据),再用infile fileref将字符代码读入变量中,接着根据待提取数据的特点对写入的观测进行“数据清洗”,最后获得所需数据观测。
大致步骤就是用filename fileref url 网页地址获取网页代码信息(包含有待提取数据),再用infile fileref将字符代码读入变量中,接着根据待提取数据的特点对写入的观测进行“数据清洗”,最后获得所需数据观测。
先针对该过程中可能出现的问题,做一下简单说明:
1.本人所用SAS软件为多国语言9.2版,刚开始运行含有filename fileref url 网页地址及infile fileref时,很不友好的显示错误:无法连接主机。这一问题困惑我好久。最后看到有前辈发帖,从一个网站http://ftp.sas.com/techsup/download/hotfix/f9_sbcs_prod_list.html#034098下载相关hot fix(F9BA26)以后,得以解决。
2.若未在infile语句中加encoding=utf-8,得出的观测乱码。
3.正则表达式并不是必须的,但是用起来简洁明了,与一些字符函数配合使用,绝对可以达到你想要的提取目的。
4.大家进入网页后,点击右键,查看源代码(有些是源文件),这个源代码就是我们需要写入数据集的文件。先用filename fileref url http://health.gmw.cn/2012-10/03/content_5266132.htm;
5.怎样将网页源文件代码写入数据集?用infile+input。不过根据写入方式不同,后续清洗数据的程序自然也不一样了。由于源代码中每一个input line的形式为<...>!!!<...>或者<...><...>(大家可以观察网页的源代码),而我们需要的数据就包含在!!!里面。而由于一个网页包含的信息太多,也有可能找到的!!!不包含所需数据。为了“清洗”数据方便,在这里我采用了一个比较笨的方法,通过观察源代码中待提取数据的大致范围,如第一个待提取字符串"黑龙江"出现在第184个input line,而最后一个"120”(澳门人均降水) 则出现在第623个input line,其他input line我们不需要,可以考虑在infile语句中加入firstobs=184 obs=623。
注意:由于网页可能发生小的变化,firstobs=与obs= 的值可能不准确,从而影响结果。建议查看源代码确定相应值。
这里介绍两种不同的写入方式。
a.以>为分隔符,写入后每个观测就形如<...或者!!!<...,而后者是我们所需保留的观测。
根据!!!<...写出对应正则表达式进行清洗。考虑用正则表达式/.+/。此种方式编程如下:
 b.源代码文件中每一个input line整体作为一个值,这样就保留了原来形式<...>!!!<...>或者<...><...>,根据>!!!<写出对应表达式进行清洗。考虑用正则表达式/>.
b.源代码文件中每一个input line整体作为一个值,这样就保留了原来形式<...>!!!<...>或者<...><...>,根据>!!!<写出对应表达式进行清洗。考虑用正则表达式/>. 
以上两种方式主要看各位的习惯吧。得到了筛选后的数据集work.newa(work.newb),数据集只含有1个变量text。而网页中则有6个变量。这是就需要对数据集work.newa做写什么了。法1.set操作:
 法2.分组transpose:
法2.分组transpose:

作者 :1989pengwei
来源 :经管之家论坛



