
作者: afenxi来源: afenxi时间:2017-06-03 13:01:11
摘要:本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取。
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取。通过使用requests库对链家网二手房列表页进行抓取,通过BeautifulSoup对页面进行解析,并从中获取房源价格,面积,户型和关注度的数据。

准备工作
首先是开始抓取前准备工作,导入需要使用的库文件,这里主要使用的是requests和BeautifulSoup两个。Time库负责设置每次抓取的休息时间。这里并非全部,后续还会在过程中导入新的库。
import requests
import time
from bs4 import BeautifulSoup
抓取列表页
开始抓取前先观察下目标页面或网站的结构,其中比较重要的是URL的结构。链家网的二手房列表页面共有100个,URL结构为http://bj.lianjia.com/ershoufang/pg9/,其中bj表示城市,/ershoufang/是频道名称,pg9是页面码。我们要抓取的是北京的二手房频道,所以前面的部分不会变,属于固定部分,后面的页面码需要在1-100间变化,属于可变部分。将URL分为两部分,前面的固定部分赋值给url,后面的可变部分使用for循环。
#设置列表页URL的固定部分
url=http://bj.lianjia.com/ershoufang/
#设置页面页的可变部分
page=(pg)
此外,还需要在很http请求中设置一个头部信息,否则很容易被封。头部信息网上有很多现成的,也可以使用httpwatch等工具来查看。具体细节按照具体情况进行调整。
#设置请求头部信息
headers = )
#查看数据表的内容
house.head()
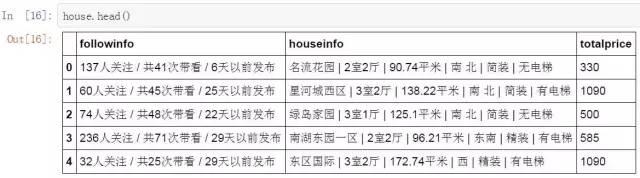
前面提取的都只是信息,还不能直接使用,在分析前要对这些信息进行数据提取和清洗等工作。如房源信息,在表中每个房源的小区名称,户型,面积,朝向等信息都在一个字段中,无法直接使用。需要先进行分列操作。这里的规则比较明显,每个信息间都是以竖线分割的,因此我们只需要以竖线进行分列即可。
#对房源信息进行分列
houseinfo_split = pd.DataFrame((x.split(|) for x in house.houseinfo),index=house.index,columns=[xiaoqu,huxing,mianji,chaoxiang,zhuangxiu,dianti])
这是完成分列后的新数据表,房源的各种信息以及成为单独的字段。
#查看分列结果
houseinfo_split.head()
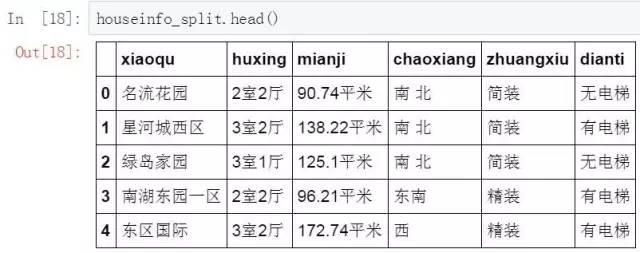
将分列后的新数据表在重新拼接回原有的数据表中,这样在后面的分析过程中可以与其他字段的信息配合使用。
#将分列结果拼接回原数据表
house=pd.merge(house,houseinfo_split,right_index=True, left_index=True)
完成拼接后的数据表中既包含了原有字段,也包含了分列后的新增字段。
#查看拼接后的数据表
house.head()
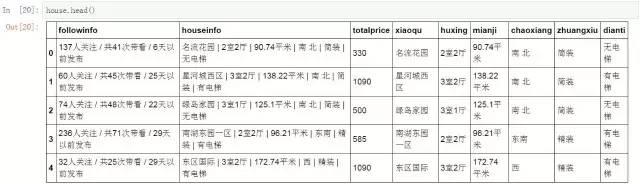
使用相同的方法对房源关注度字段进行分列和拼接操作。这里的分列规则是斜杠。
#对房源关注度进行分列
followinfo_split = pd.DataFrame((x.split(/) for x in house.followinfo),index=house.index,columns=[guanzhu,daikan,fabu])
#将分列后的关注度信息拼接回原数据表
house=pd.merge(house,followinfo_split,right_index=True, left_index=True)
房源户型分布情况
前面我们经过对房源信息的分列获取了房源的朝向,户型等信息,这里我们对房源的户型情况进行汇总,看看北京在售二手房的户型分布情况。
首先按房源的户型对房源数量进行汇总,下面是具体的代码和结果。
#按房源户型类别进行汇总
huxing=house.groupby(huxing)[huxing].agg(len)
#查看户型汇总结果
huxing

导入数值计算库mumpy对数据进行处理,并使用matplotlib绘制房源户型分布条形图。
#导入图表库
import matplotlib.pyplot as plt
#导入数值计算库
import numpy as np
#绘制房源户型分布条形图
plt.rc(font, family=STXihei, size=11)
a=np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
plt.barh([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],huxing,color=#052B6C,alpha=0.8,align=center,edgecolor=white)
plt.ylabel(户型)
plt.xlabel(数量)
plt.xlim(0,1300)
plt.ylim(0,20)
plt.title(房源户型分布情况)
plt.legend([数量], loc=upper right)
plt.grid(color=#95a5a6,linestyle=--, linewidth=1,axis=y,alpha=0.4)
plt.yticks(a,(1室0厅,1室1厅,1室2厅,2室0厅,2室1厅,2室2厅,3室0厅,3室1厅,3室2厅,3室3厅,4室1厅,4室2厅,4室3厅,5室2厅,5室3厅,6室1厅,6室2厅,7室2厅,7室3厅))
plt.show()
北京在售二手房中户型从1室0厅到7室3厅近20种分布广泛。在所有的户型中数量最多的是2室1厅,其次为3室1厅和3室2厅,以及2室2厅。较小的1室1厅数量也较多。较大的户型数量较少。另外,从在售户型的分布中我们也可以推测出售房人的一些情况。
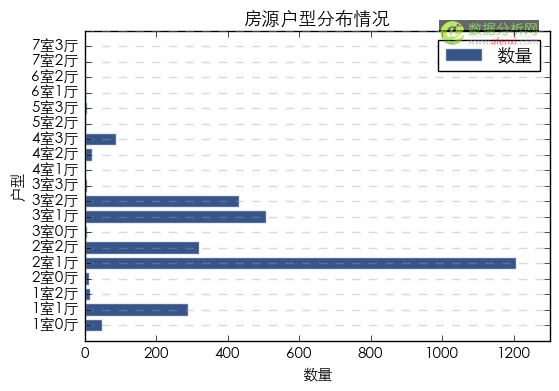
房源面积分布情况
在数据表中,房源面积通过分列以及单独提取出来,但数字与中文的格式并不能直接使用。我们还需要对房源面积字段进行二次分列处理,提取出面积的数值。方法与前面的分列方法类似,我们使用“平”作为分列规则对房源面积进行二次分列。并将分列后的结果拼接回原数据表中。
#对房源面积进行二次分列
mianji_num_split = pd.DataFrame((x.split(平) for x in house.mianji),index=house.index,columns=[mianji_num,mi])
#将分列后的房源面积拼接回原数据表
house=pd.merge(house,mianji_num_split,right_index=True, left_index=True)
分列后的数据在使用前还需要进行清洗,通常的操作包括去除空格和格式转换。下面我们先对房源面积的值去除两端的空格,然后更改数值的格式以方便后面的计算。
#去除mianji_num字段两端的空格
house[mianji_num]=house[mianji_num].map(str.strip)
#更改mianji_num字段格式为float
house[mianji_num]=house[mianji_num].astype(float)
清洗后的房源面积字段可以开始分析了。首先查看所有北京在售二手房的面积范围,下面是代码和结果。房源面积从18.85到332.63。
#查看所有房源面积的范围值
house[mianji_num].min(),house[mianji_num].max()
(18.850000000000001, 332.63)
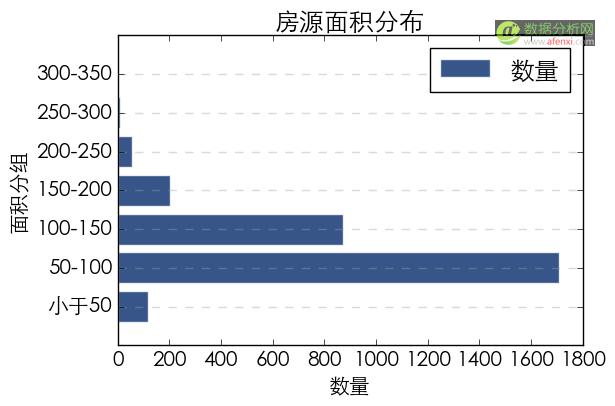
有了房源面积的范围后,就可以对面积进行分组了,我们以50为区间将房源面积分为7组。并统计所有房源在这7组中的分布情况。
#对房源面积进行分组
bins = [0, 50, 100, 150, 200, 250, 300, 350]
group_mianji = [小于50, 50-100, 100-150, 150-200,200-250,250-300,300-350]
house[group_mianji] = pd.cut(house[mianji_num], bins, labels=group_mianji)
#按房源面积分组对房源数量进行汇总
group_mianji=house.groupby(group_mianji)[group_mianji].agg(len)
使用房源面积分组字段对房源数量进行分组并绘制条形图。
#绘制房源面积分布图
plt.rc(font, family=STXihei, size=15)
a=np.array([1,2,3,4,5,6,7])
plt.barh([1,2,3,4,5,6,7],group_mianji,color=#052B6C,alpha=0.8,align=center,edgecolor=white)
plt.ylabel(面积分组)
plt.xlabel(数量)
plt.title(房源面积分布)
plt.legend([数量], loc=upper right)
plt.grid(color=#95a5a6,linestyle=--, linewidth=1,axis=y,alpha=0.4)
plt.yticks(a,(小于50, 50-100, 100-150, 150-200,200-250,250-300,300-350))
plt.show()
在所有房源中,数量最多的是50-100,其次为100-150。随着面积增加数量减少。小于50的小面积房源也有一定数量的房源。
房源关注度分布情况
房源关注度的情况与房源面积类似,第一次分列处理后得到的数据包含数字和中文,无法直接使用,需要再次通过分列处理提取关注度的数值,并对数值进行清洗和格式转换。下面是具体的代码。
#对房源关注度进行二次分列
guanzhu_num_split = pd.DataFrame((x.split(人) for x in house.guanzhu),index=house.index,columns=[guanzhu_num,ren])
#将分列后的关注度数据拼接回原数据表
house=pd.merge(house,guanzhu_num_split,right_index=True, left_index=True)
#去除房源关注度字段两端的空格
house[guanzhu_num]=house[guanzhu_num].map(str.strip)
#更改房源关注度及总价字段的格式
house[[guanzhu_num,totalprice]]=house[[guanzhu_num,totalprice]].astype(float)
清洗完后查看所有房源关注度的区间,关注度从0到725。也就是说有些房子很热门,而有些房子没有人关注。这可能和房源上线和更新的情况有关,此外还要考虑房源的销售速度,热门房源可能很抢手,刚上线就成交了。因此我们对情况进行简化,暂时忽略掉这些复杂的情况。仅对关注度的分布情况进行统计。
#查看房源关注度的区间
house[guanzhu_num].min(),house[guanzhu_num].max()
(0.0, 725.0)
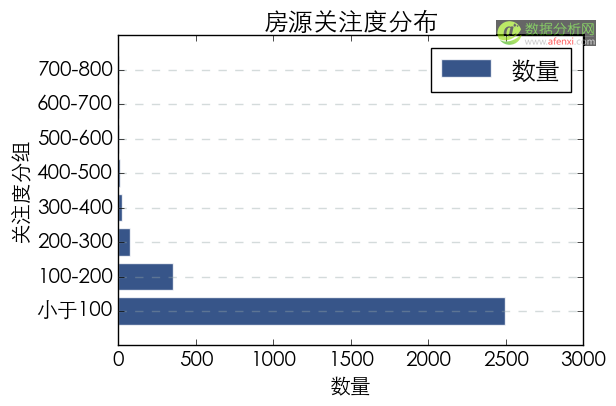
将关注度以100为区间分为8组,并按关注度区间进行汇总统计房源数量。查看在售房源的关注度分布情况。
#对房源关注度进行分组
bins = [0, 100, 200, 300, 400, 500, 600, 700,800]
group_guanzhu = [小于100, 100-200, 200-300, 300-400,400-500,500-600,600-700,700-800]
house[group_guanzhu] = pd.cut(house[guanzhu_num], bins, labels=group_guanzhu)
group_guanzhu=house.groupby(group_guanzhu)[group_guanzhu].agg(len)
绘制房源关注度分布条形图。
#绘制房源关注度分布图
plt.rc(font, family=STXihei, size=15)
a=np.array([1,2,3,4,5,6,7,8])
plt.barh([1,2,3,4,5,6,7,8],group_guanzhu,color=#052B6C,alpha=0.8,align=center,edgecolor=white)
plt.ylabel(关注度分组)
plt.xlabel(数量)
plt.xlim(0,3000)
plt.title(房源关注度分布)
plt.legend([数量], loc=upper right)
plt.grid(color=#95a5a6,linestyle=--, linewidth=1,axis=y,alpha=0.4)
plt.yticks(a,(小于100, 100-200, 200-300, 300-400,400-500,500-600,600-700,700-800))
plt.show()
在3000个房源中,近2500个房源的关注度小于100,关注度大于400的房源则较少。这里需要再次说明的是关注度数据无法准确的表示房源的热门程度。热门房源可能由于出售速度快而关注度较少。因此关注度数据仅供参考。
房源聚类分析
最后,我们对所有在售房源按总价,面积和关注度进行聚类分析。将在售房源按总价,面积和关注度的相似性分在不同的类别中。
#导入sklearn中的KMeans进行聚类分析
from sklearn.cluster import KMeans
#使用房源总价,面积和关注度三个字段进行聚类
house_type = np.array(house[[totalprice,mianji_num,guanzhu_num]])
#设置质心数量为3
clf=KMeans(n_clusters=3)
#计算聚类结果
clf=clf.fit(house_type)
通过计算我们将在售房源分为三个类别,下面是每个类别的中心点坐标。
#查看分类结果的中心坐标
clf.cluster_centers_
array([[ 772.97477064, 112.02389908, 58.96330275],
[ 434.51073861, 84.92950236, 61.20115244],
[ 1473.26719577, 170.65402116, 43.32275132]])
#在原数据表中标注所属类别
house[label]= clf.labels_
根据三个类别在总价,面积和关注度三个点的中心坐标,我们将在售房源分为三个类别,第一个类别是总价低,面积低,关注度高的房源。第二个类别是总价居中,面积居中,关注度居中的类别。第三个类别是总价高,面积高,关注度低的类别。

从营销和用户体验的角度来看,在广告和列表页的默认排序中应该给予总价400万,面积80属性的房源更高的权重。这个类别的房源可以吸引最多的用户关注。



