
作者: afenxi来源: afenxi时间:2017-07-14 17:16:56
摘要:我一直认为佛爷(陈伟霆)是主演,也让我对这二位谁是主角产生的好奇,于是决定用R语言进行文本统计一下,证明谁是男1,谁是男2。
本人最近看了老九门,两大男主角都是颜值担当,我的朋友中有喜欢佛爷(陈伟霆),有的喜欢二爷(张艺兴)。从我的朋友中发现更多人倾向于张艺兴扮演的二爷,他们认为二爷(张艺兴)是男1号。但是从出场次数和演员表排名佛爷(陈伟霆)都在二爷(张艺兴)之前。我一直认为佛爷(陈伟霆)是主演,也让我对这二位谁是主角产生的好奇,于是决定用R语言进行文本统计一下,证明谁是男1,谁是男2。目前关于R文本挖掘的方法已经有很多了,这里再简单介绍一下。进而论述结果。代码如下:
#####首先,加载所需要的工具包
######注意rJava需要jdk环境
library(rJava) library(Rwordseg) library("RColorBrewer") library("wordcloud")
##########接下来要自定义加载词,因为二月红并不是传统意义的词语,如果不单独加载会被分成二月,红。两个词。
##########加载方法有很多,本人选择最简单的加载单个词语方法insertWords,deleteWords为删除该词
####insertWords("二月红")
###deleteWords("二月红")
#接下来就是正常的统计词频,小说数据在附件
myfile<-read.csv(file.choose(),header=FALSE) myfile.res <- myfile[myfile!=" "] myfile.words <- unlist(lapply(X = myfile.res,FUN = segmentCN)) myfile.words <- gsub(pattern="http:[a-zA-Z/.0-9]+","",myfile.words) myfile.words <- gsub(" ","",myfile.words) myfile.words <- gsub(" ","",myfile.words) myfile.words<-subset(myfile.words,nchar(as.character(myfile.words))>1) myfile.freq <- table(unlist(myfile.words)) myfile.freq <- rev(sort(myfile.freq)) myfile.freq <- data.frame(word=names(myfile.freq), freq=myfile.freq); myfile.freq2=subset(myfile.freq, myfile.freq$freq>=2)
#####从统计结果,可以看出佛爷出现的次数的确大于二月红
##将统计结果在画出词云展现一下,目前词云的形状可视化多种多样,本人用最简单的方式进行展现
#画图
mycolors <- brewer.pal(8,"Dark2") windowsFonts(myFont=windowsFont("华文彩云")) wordcloud(myfile.freq$word,myfile.freq$freq,min.freq=3,random.order=FALSE,random.color=FALSE,colors=mycolors,family="myFont") 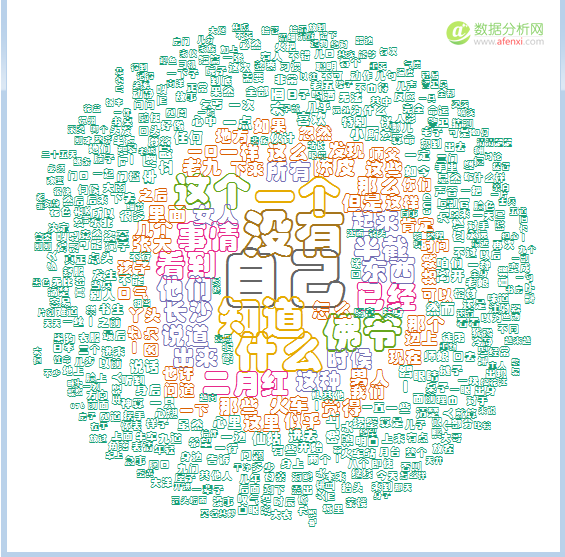
从可视化展现看出佛爷字体大小大于二月红。
因此,从原著来讲,佛爷为男1,二月红为男2。
代码部分.zip 老九门.zip
作者:张聪,从事多个大型零售商,省运营商数据挖掘咨询工作。



