
作者: afenxi来源: afenxi时间:2016-12-16 15:38:21
摘要:本篇文章通过python与excel的功能对比介绍如何使用python通过函数式编程完成excel中的数据处理及分析工作
Excel是数据分析中最常用的工具,本篇文章通过python与excel的功能对比介绍如何使用python通过函数式编程完成excel中的数据处理及分析工作。在Python中pandas库用于数据处理,我们从1787页的pandas官网文档中总结出最常用的36个函数,通过这些函数介绍如何通过python完成数据生成和导入,数据清洗,预处理,以及最常见的数据分类,数据筛选,分类汇总,透视等最常见的操作。
这个系列文章内容共分为9个部分。已由人民邮电出版社出版,感兴趣的朋友可以在异步社区获取完整版。

前两篇文章链接在这里:
像Excel一样使用python进行数据分析-(1)
像Excel一样使用python进行数据分析-(2)
这是第三篇,介绍第7-9部分的内容,数据汇总,数据统计,和数据输出。
 7,数据汇总
7,数据汇总
第七部分是对数据进行分类汇总,Excel中使用分类汇总和数据透视可以按特定维度对数据进行汇总,python中使用的主要函数是groupby和pivot_table。下面分别介绍这两个函数的使用方法。
分类汇总
Excel的数据目录下提供了“分类汇总”功能,可以按指定的字段和汇总方式对数据表进行汇总。Python中通过Groupby函数完成相应的操作,并可以支持多级分类汇总。
 Groupby是进行分类汇总的函数,使用方法很简单,制定要分组的列名称就可以,也可以同时制定多个列名称,groupby按列名称出现的顺序进行分组。同时要制定分组后的汇总方式,常见的是计数和求和两种。
Groupby是进行分类汇总的函数,使用方法很简单,制定要分组的列名称就可以,也可以同时制定多个列名称,groupby按列名称出现的顺序进行分组。同时要制定分组后的汇总方式,常见的是计数和求和两种。
1 2 #对所有列进行计数汇总 df_inner.groupby(city).count() 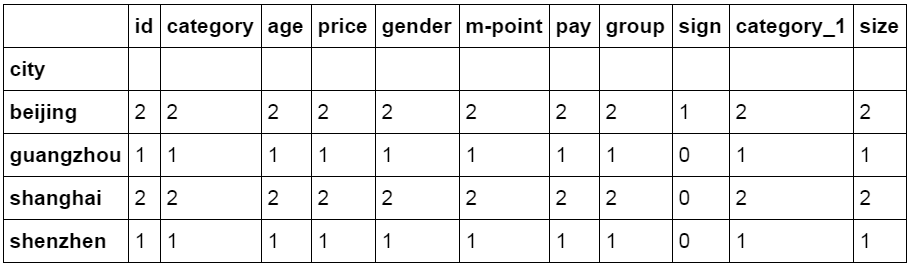
可以在groupby中设置列名称来对特定的列进行汇总。下面的代码中按城市对id字段进行汇总计数。
1 2 3 4 5 6 7 8 #对特定的ID列进行计数汇总 df_inner.groupby(city)[id].count() city beijing 2 guangzhou 1 shanghai 2 shenzhen 1 Name: id, dtype: int64
在前面的基础上增加第二个列名称,分布对city和size两个字段进行计数汇总。
1 2 3 4 5 6 7 8 9 10 #对两个字段进行汇总计数 df_inner.groupby([city,size])[id].count() city size beijing A 1 F 1 guangzhou A 1 shanghai A 1 B 1 shenzhen C 1 Name: id, dtype: int64
除了计数和求和外,还可以对汇总后的数据同时按多个维度进行计算,下面的代码中按城市对price字段进行汇总,并分别计算price的数量,总金额和平均金额。
1 2 #对city字段进行汇总并计算price的合计和均值。 df_inner.groupby(city)[price].agg([len,np.sum, np.mean]) 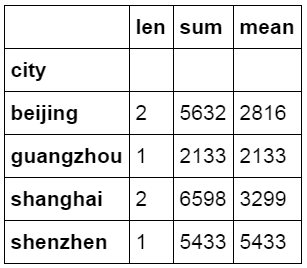 数据透视
数据透视
Excel中的插入目录下提供“数据透视表”功能对数据表按特定维度进行汇总。Python中也提供了数据透视表功能。通过pivot_table函数实现同样的效果。  数据透视表也是常用的一种数据分类汇总方式,并且功能上比groupby要强大一些。下面的代码中设定city为行字段,size为列字段,price为值字段。分别计算price的数量和金额并且按行与列进行汇总。
数据透视表也是常用的一种数据分类汇总方式,并且功能上比groupby要强大一些。下面的代码中设定city为行字段,size为列字段,price为值字段。分别计算price的数量和金额并且按行与列进行汇总。
1 2 #数据透视表 pd.pivot_table(df_inner,index=["city"],values=["price"],columns=["size"],aggfunc=[len,np.sum],fill_value=0,margins=True) 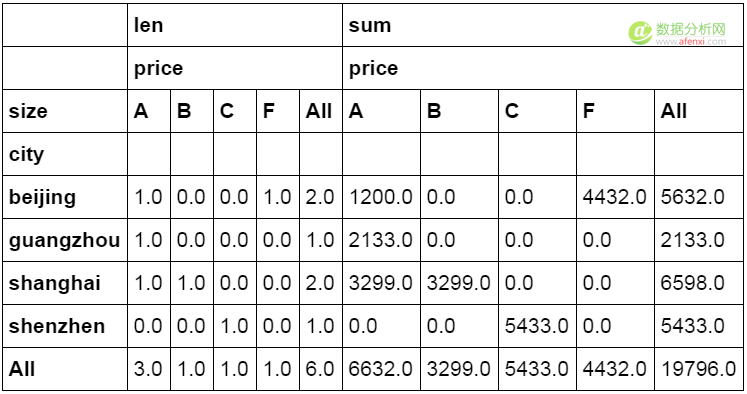 8,数据统计
8,数据统计
第九部分为数据统计,这里主要介绍数据采样,标准差,协方差和相关系数的使用方法。
数据采样
Excel的数据分析功能中提供了数据抽样的功能,如下图所示。Python通过sample函数完成数据采样。

Sample是进行数据采样的函数,设置n的数量就可以了。函数自动返回参与的结果。
1 2 #简单的数据采样 df_inner.sample(n=3) 
Weights参数是采样的权重,通过设置不同的权重可以更改采样的结果,权重高的数据将更有希望被选中。这里手动设置6条数据的权重值。将前面4个设置为0,后面两个分别设置为0.5。
1 2 3 #手动设置采样权重 weights = [0, 0, 0, 0, 0.5, 0.5] df_inner.sample(n=2, weights=weights) 
从采样结果中可以看出,后两条权重高的数据被选中。
 Sample函数中还有一个参数replace,用来设置采样后是否放回。
Sample函数中还有一个参数replace,用来设置采样后是否放回。
1 2 #采样后不放回 df_inner.sample(n=6, replace=False)  1 2 #采样后放回 df_inner.sample(n=6, replace=True)
1 2 #采样后放回 df_inner.sample(n=6, replace=True)  描述统计
描述统计
Excel中的数据分析中提供了描述统计的功能。Python中可以通过Describe对数据进行描述统计。

Describe函数是进行描述统计的函数,自动生成数据的数量,均值,标准差等数据。下面的代码中对数据表进行描述统计,并使用round函数设置结果显示的小数位。并对结果数据进行转置。
1 2 #数据表描述性统计 df_inner.describe().round(2).T
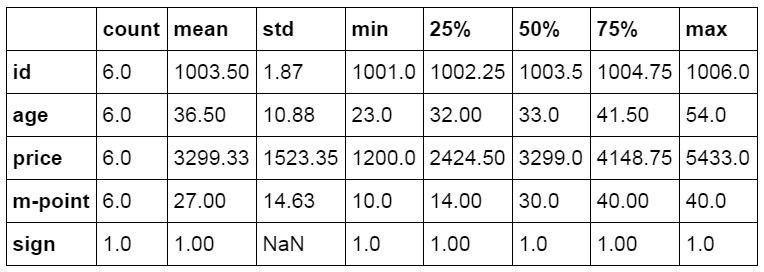 标准差 Python中的Std函数用来接算特定数据列的标准差。
标准差 Python中的Std函数用来接算特定数据列的标准差。
1 2 3 #标准差 df_inner[price].std() 1523.3516556155596
协方差 Excel中的数据分析功能中提供协方差的计算,python中通过cov函数计算两个字段或数据表中各字段间的协方差。

Cov函数用来计算两个字段间的协方差,可以只对特定字段进行计算,也可以对整个数据表中各个列之间进行计算。
1 2 3 #两个字段间的协方差 df_inner[price].cov(df_inner[m-point]) 17263.200000000001 1 2 #数据表中所有字段间的协方差 df_inner.cov() 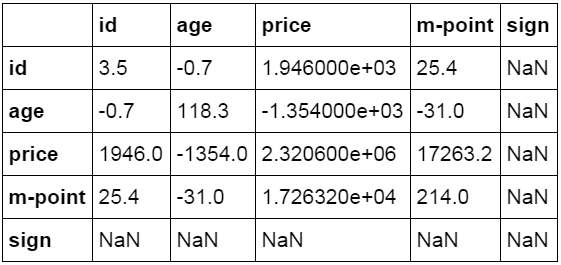
相关分析 Excel的数据分析功能中提供了相关系数的计算功能,python中则通过corr函数完成相关分析的操作,并返回相关系数。

Corr函数用来计算数据间的相关系数,可以单独对特定数据进行计算,也可以对整个数据表中各个列进行计算。相关系数在-1到1之间,接近1为正相关,接近-1为负相关,0为不相关。
1 2 3 #相关性分析 df_inner[price].corr(df_inner[m-point]) 0.77466555617085264 1 2 #数据表相关性分析 df_inner.corr() 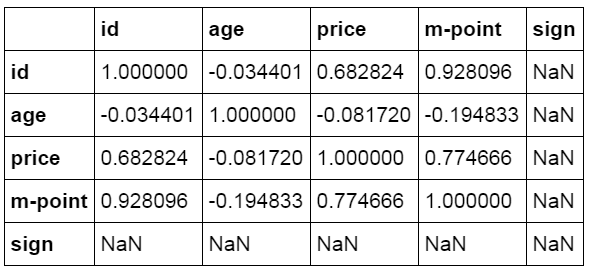 9,数据输出
9,数据输出
第九部分是数据输出,处理和分析完的数据可以输出为xlsx格式和csv格式。
写入excel
1 2 #输出到excel格式 df_inner.to_excel(excel_to_python.xlsx, sheet_name=bluewhale_cc)
 写入csv
写入csv
1 2 #输出到CSV格式 df_inner.to_csv(excel_to_python.csv)
在数据处理的过程中,大部分基础工作是重复和机械的,对于这部分基础工作,我们可以使用自定义函数进行自动化。以下简单介绍对数据表信息获取自动化处理。
1 2 3 4 5 6 7 8 #创建数据表 df = pd.DataFrame(, columns =[id,date,city,category,age,price]) 1 2 3 4 5 6 7 8 #创建自定义函数 def table_info(x): shape=x.shape types=x.dtypes colums=x.columns print("数据维度(行,列): ",shape) print("数据格式: ",types) print("列名称: ",colums) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #调用自定义函数获取df数据表信息并输出结果 table_info(df) 数据维度(行,列): (6, 6) 数据格式: id int64 date datetime64[ns] city object category object age int64 price float64 dtype: object 列名称: Index([id, date, city, category, age, price], dtype=object)
本篇是《像Excel一样使用python进行数据分析》系列文章的最后一篇。在这个系列中我们列举了python中36个简单的函数来实现excel中最常见的一些功能。感兴趣的朋友可以下载并阅读pandas官方文档,里面有更详细的函数说明。也欢迎给我留言进行交流。



