
作者: afenxi来源: afenxi时间:2016-12-27 10:55:35
基于 Python 的顾客细分
在这篇文章中,我要谈的东西是相对简单,但却是对任何业务都很重要的:客户细分。客户细分的核心是能够识别不同类型的客户,然后知道如何找到更多这样的人,这样你就可以…你猜对了,获得更多的客户!在这篇文章中,我将详细介绍您如何可以使用K-均值聚类来完成一些客户细分方面的探索。
我们的数据
我们使用的数据来自 John Foreman 的《智能数据》。该数据集包含了营销快讯/电邮推广(电子邮件发送报价)和来自客户的交易层面数据(提供的数据来自客户期望和最终购买)这两个信息。
Python 1 2 3 4 import pandas as pd df_offers = pd.read_excel("./WineKMC.xlsx", sheetname=0) df_offers.columns = ["offer_id", "campaign", "varietal", "min_qty", "discount", "origin", "past_peak"] df_offers.head() 
交易层面的数据…
Python 1 2 3 4 df_transactions = pd.read_excel("./WineKMC.xlsx", sheetname=1) df_transactions.columns = ["customer_name", "offer_id"] df_transactions[n] = 1 df_transactions.head()
 K-均值快速入门
K-均值快速入门
为了细分客户,我们需要一种方法来对它们进行比较。要做到这一点,我们将使用K-均值聚类。K-均值是一种获取一个数据集,并从中发现具有类似性质点的组合(或簇)的方法。K-均值的工作原理是,最小化各个点与各簇中点之间的距离,并以此来进行分组。
想一个最简单的例子。如果我告诉你为下面这些点创建 3 个组,并在每个组的中间绘制一个星星,你会怎么做?
可能(或希望)是这样的…
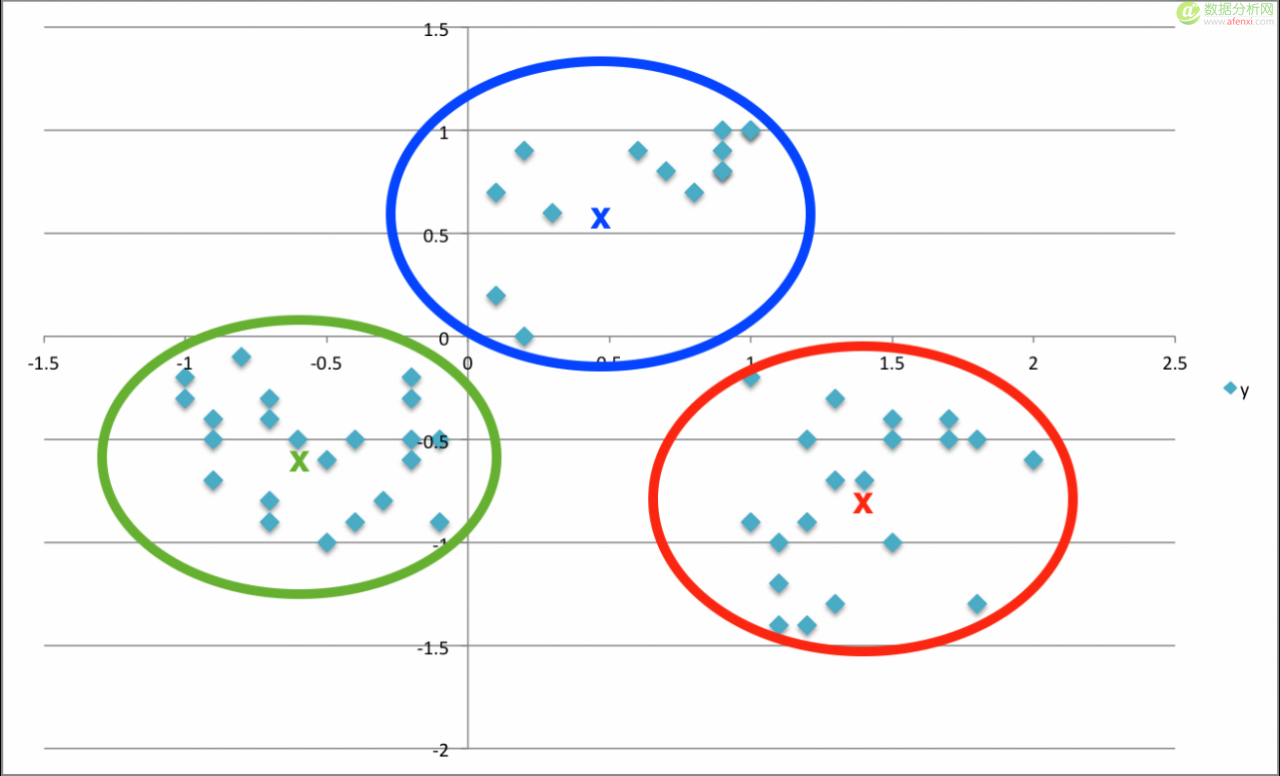
在K-均值中,“ x ”的被称为“重心”,并指出(你猜对了),给定簇的中心。我不打算详细讲述K-均值实际上是怎什么样运作的,但希望这说明会给你一个不错的想法。
将客户分类
好吧,那么,如何我们的客户该怎么分类呢?因为我们试图更多地了解我们客户的行为,我们可以用他们的行为(根据他们是否在收到报价后进行了采购),以此将有类似想法的客户分类在一起。然后,我们可以研究这些群体,来寻找模式和趋势,来帮助我们制定未来的报价。
我们最需要的就是一种比较客户的方法。要做到这一点,我们要创建一个矩阵,包含每个客户和他们是否回应了报价的一个 0/1 指标。在 Python 中,这是很容易做到的:
Python 1 2 3 4 5 6 7 8 # join the offers and transactions table df = pd.merge(df_offers, df_transactions) # create a "pivot table" which will give us the number of times each customer responded to a given offer matrix = df.pivot_table(index=[customer_name], columns=[offer_id], values=n) # a little tidying up. fill NA values with 0 and make the index into a column matrix = matrix.fillna(0).reset_index() # save a list of the 0/1 columns. well use these a bit later x_cols = matrix.columns[1:]
现在创建簇,我们将使用 scikit-learn 库中 KMeans 的功能。我任意选择了 5 个簇。我一般的经验法则是,我进行分类的记录数至少是类别数的 7 倍。
Python 1 2 3 4 5 6 7 8 9 10 11 from sklearn.cluster import KMeans cluster = KMeans(n_clusters=5) # slice matrix so we only include the 0/1 indicator columns in the clustering matrix[cluster] = cluster.fit_predict(matrix[matrix.columns[2:]]) matrix.cluster.value_counts() 2 32 1 22 4 20 0 15 3 11 dtype: int64 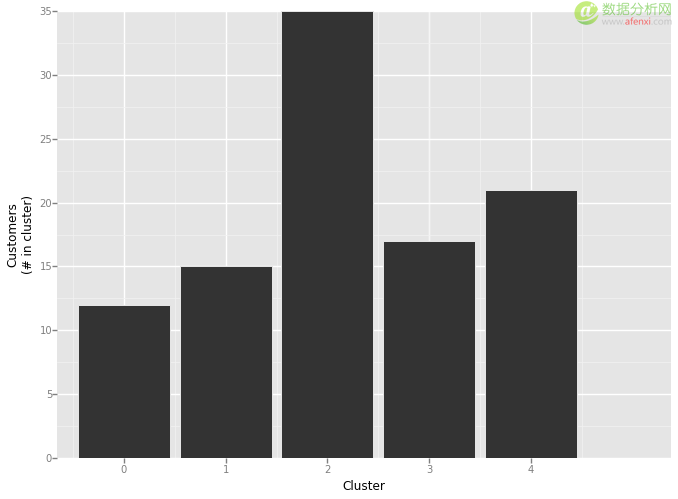
簇可视化
一个很酷的技巧,这可能是学校没有教你的,主成分分析。它有很多用途,但今天我们将用它来将我们的多维数据集转化到一个二维数据集。 你问为什么要这样做?一旦它在二维中(或简单地说,它有 2 列),它就会变得更容易绘制!
再一次, scikit-learn 发挥作用了!
Python 1 2 3 4 5 6 7 8 9 from sklearn.decomposition import PCA pca = PCA(n_components=2) matrix[x] = pca.fit_transform(matrix[x_cols])[:,0] matrix[y] = pca.fit_transform(matrix[x_cols])[:,1] matrix = matrix.reset_index() customer_clusters = matrix[[customer_name, cluster, x, y]] customer_clusters.head() 
我们所做的就是我们把 x_cols 列设定为 0/1 指标变量,我们已经把他们变成了一个二维的数据集。我们任取一列,称之为 x,然后把其余剩下的叫 y。现在我们可以把每一个点都对应到一个散点图中。我们将基于它的簇编码每个点的颜色,可以让它们更清晰。
Python 1 2 3 4 5 6 7 8 df = pd.merge(df_transactions, customer_clusters) df = pd.merge(df_offers, df) from ggplot import * ggplot(df, aes(x=x, y=y, color=cluster)) + geom_point(size=75) + ggtitle("Customers Grouped by Cluster") 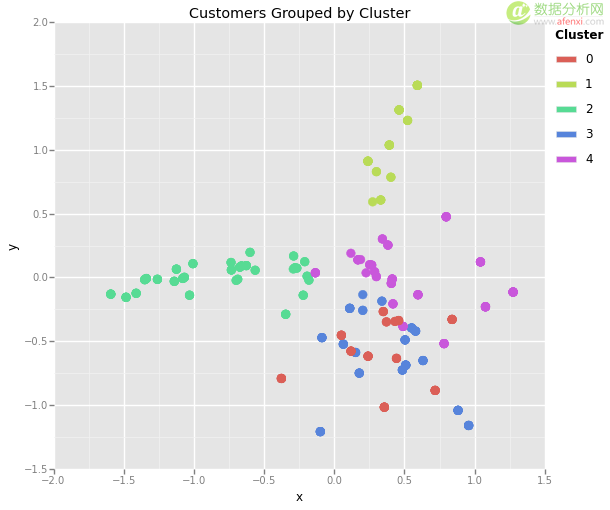
如果你要搞点花样,你也可以画出各簇的中心。这些都存储在 KMeans 实例中的 cluster_centers_ 变量。确保你也可以将簇心转换为二维投影。
Python 1 2 3 4 5 6 7 8 cluster_centers = pca.transform(cluster.cluster_centers_) cluster_centers = pd.DataFrame(cluster_centers, columns=[x, y]) cluster_centers[cluster] = range(0, len(cluster_centers)) ggplot(df, aes(x=x, y=y, color=cluster)) + geom_point(size=75) + geom_point(cluster_centers, size=500) + ggtitle("Customers Grouped by Cluster") 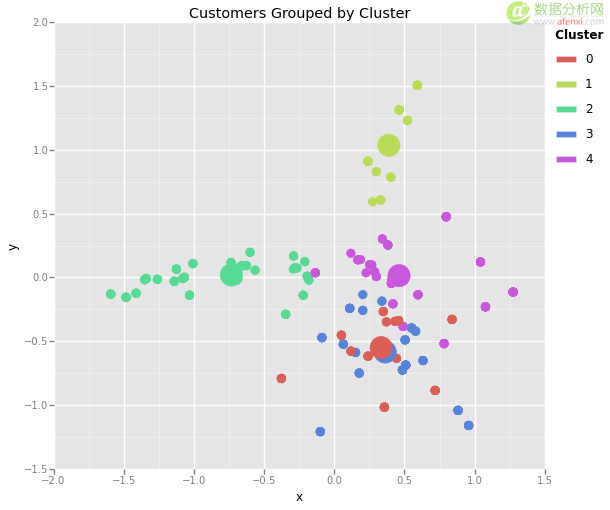
对簇更深的挖掘
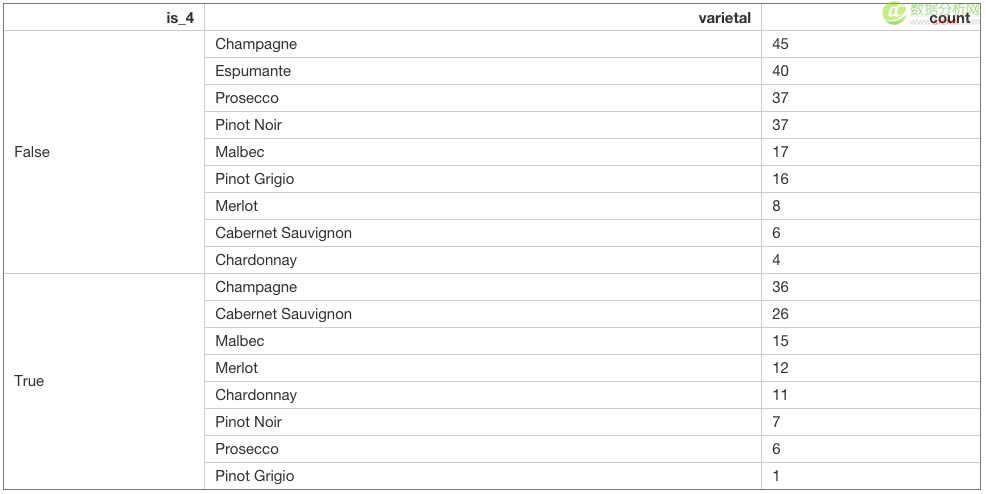
让我们在簇中更深入得挖掘吧。以第 4 簇为例。如果我们挑出簇4,并将其与余下的客户比较,我们就可以开始寻找可供我们利用的、有趣的方方面面。
作为一个基准,看看簇4与其它簇的葡萄品种对比。事实证明,几乎所有的Cabernet Sauvignon(赤霞珠)都是由簇4的成员购买的。另外,簇4中没有一个人买了Espumante(意大利苏打白葡萄酒)。
Python 1 2 df[is_4] = df.cluster==4 df.groupby("is_4").varietal.value_counts()
 你还可以细分出数值功能。例如,看看为何4号簇与其它簇在min_qty的平均值上表现迥异。似乎簇4的成员都喜欢大批量购买!
你还可以细分出数值功能。例如,看看为何4号簇与其它簇在min_qty的平均值上表现迥异。似乎簇4的成员都喜欢大批量购买!
Python 1 df.groupby("is_4")[[min_qty, discount]].mean() 

结语
虽然它不会神奇地告诉你所有的答案,但分群是一个很好的探索性尝试,可以帮助你更多地了解你的客户。有关K-均值和客户细分的更多信息,请查看以下资源:
INSEAD Analytics Cluster Analysis and Segmentation Post Customer Segmentation at Bain & Company Customer Segmentation Wikipedia
这篇所用代码请查阅 这里。
本文由 伯乐在线 - 高冷的精神污染 翻译,toolate 校稿。 英文出处:Greg。
原创文章,作者:古思特,如若转载,请注明出处:《Python中用K-均值聚类来探索顾客细分》http://www.afenxi.com/post/10571



