
作者: afenxi来源: afenxi时间:2017-04-14 11:21:06
摘要:在微博上收藏了一个技术贴,作者是 Savvs Tjortjoglou(Twitter:@savvas_tj)。他之前的一篇NBA投篮绘图在内地网络上挺火的,几个微信公号都有推,今天看的这一个帖子原题是:How to Track NBA Player Movements in Python,我尝试着模拟了一遍,加了一点自己的元素,感觉非常不错!
首先,可以进入NBA官网的stats看看,非常详细的统计,主菜单栏里Stats中有一个SportVU Player Tracking,当然还有Team Tracking。里面的可视化呈现相当美观。Intro里写到:Player Tracking is the latest example of how technology and statistics are changing the way we understand the game of basketball. 大数据的力量的确给传统运动带来了革兴,SportVU是一个软件,它依靠NBA赛场过道(catwalks)上安装的6台摄像机,追踪赛场上每个运动员和篮球本身的移动轨迹,追踪速度是25次/s,通过处理,摄像机收集到的数据为运动速度、运动距离、球员间距、控球等要素的分析提供了极为丰富的统计数据库。
对于美国的运动数据统计能力感到惊讶!但强大的Python当然可以在自我理解下处理这些丰富的数据。
Part 1. 引入模块
导入的模块大多数是比较常用的。其中的seaborn是一个统计数据可视化模块,画出的图形很美观,实际上在后面的操作中几乎没有用seaborn画图,还是依靠pandas、matplotlib组合。
import seaborn as sns, numpy as np, requests, pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.display import IFrame
因为是可视化,接下来设计画布风格和颜色,直接参考seaborn文档,五种风格分别是:darkgrid,whitegrid,dark,white,ticks。写以下两行代码:
sns.set_color_codes()
sns.set_style(white)
接着,用IFrame导入一个网站上的既有Demo。
IFrame("http://stats.nba.com/movement/#!/?GameID=0041400235&GameEventID=308", width = 700, height = 400)
IFrame可以将任何网页导入到IPython Notebook,其他的IDE应该也有类似的嵌入工具。
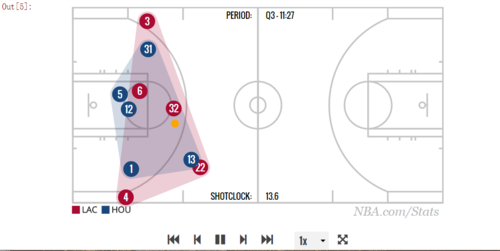
是个动态小视频,发现IFrame这么好玩,我接下来导入一个自己原来的Tableau作品,效果也是同样好。
IFrame("https://public.tableau.com/profile/luochen#!/vizhome/_2861/BibleCrossReference", width = 800, height = 1000)
 Part 2. 获取数据
Part 2. 获取数据
NBA官网数据库有API,两个参数:evenid,gameid。后者是这个playoff game的id。用Requests来解析网页而不是用urllib2,我感觉比较奇怪,但是之前也有用过Requests,发现它的slogan是HTTP for Humans,好大的口气!但是操作,尤其是对API的操作较urllib2简化了很多。
url = "http://stats.nba.com/stats/locations_getmoments/?eventid=308&gameid=0041400235"
r = requests.get(url)
r.json().keys()
轻松把源网页转成json格式,并读取所有键,共5个:
[umoments, uvisitor, ugamedate, ugameid, uhome]
我们需要的数据主要是:
home:主场队员的数据
visitor:客场队员的数据
moments:用来绘制运动轨迹的数据
所以接下来就明晰了:
home = r.json()[home]
visitor = r.json()[visitor]
moments = r.json()[moments]
前面两个都print一下,结构都很明确直观。
moments是结构最为浩大的数据,毕竟是摄像机每秒25次得到的,先看看它的长度,是700,所以撷一叶而知秋。
moments[0]
结构是这样的,说明就添在后面了:
[3, #赛季,period or quarter
1431486313010L, #时间戳unix-time in mills, 转为可读时间大概是:05/13/2015 3:05am UTC
715.32, #距离比赛结束的时间,game clock
19.0, #距离投球结束的时间,shot clock
None, #不懂,反正是空值就不必要care
[[-1, -1, 43.51745, 10.76997, 1.11823], #关于球的信息,前两个数是比赛双方的teamid和playerid;中间两个数是球在球场上的坐标,最后一个数是球的半径,球越高半径越大。
[1610612745, 1891, 43.21625, 12.9461, 0.0], #后10个列表是关于球场上10个队员的信息。意义和第一个关于球的信息列表一致。
[1610612745, 2772, 90.84496, 7.79534, 0.0],
[1610612745, 2730, 77.19964, 34.36718, 0.0],
[1610612745, 2746, 46.24382, 21.14748, 0.0],
[1610612745, 201935, 81.0992, 48.10742, 0.0],
[1610612746, 2440, 88.12605, 11.23036, 0.0],
[1610612746, 200755, 84.41011, 43.47075, 0.0],
[1610612746, 101108, 46.18569, 16.49072, 0.0],
[1610612746, 201599, 78.64683, 31.87798, 0.0],
[1610612746, 201933, 65.89714, 25.57281, 0.0]]]
最理想的数据分析模型是pandas的数据框,所以为数据框的建立做准备,接下来的一个代码段就是Python基础。
headers = [team_id, player_id, x_loc, y_loc, radius, moment, game_clock, shot_clock]
player_moments = []
for moment in moments:
for player in moment[5]:
player.extend((moments.index(moment)#索引值, moment[2]#game clock, moment[3]#shot clock)) #扩展列表
player_moments.append(player) #扩展空列表
player_moments[0: 11]
非常规整的列表,列表中的每个构成元素也是列表,和上面的样式基本保持一致。接下来构建DataFrame。
df = pd.DataFrame(player_moments, columns = headers)
df.head(11)
最好加上运动员名字,会方便后续分析。
players = home[players]
players.extend(visitor[players]) #所有运动员的名字
id_dict =
for player in players:
id_dict[player[playerid]] = [player[firstname] +" " + player[lastname], player[jersey]]
id_dict
是一个规整的字典,内部的值是列表。
用map方法来在原来的df中添加一列play_name列和player_jersey列,根据player_id来把name和jersey对应在正确的位置。写完这一段代码后,我觉得这里的map方法和Excel中的VLOOKUP十分相似,可见数据分析的内核是相通的。
df[player_name] = df.player_id.map(lambda x: id_dict[x][0])
df[player_jersey] = df.player_id.map(lambda x: id_dict[x][1])
df.head(11)
Part 3. 绘制
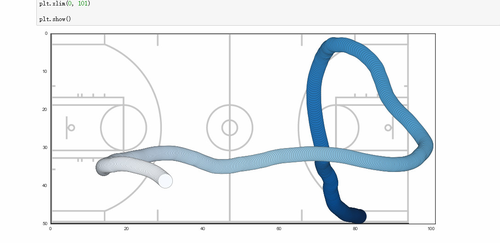
可以选择任何一位运动员来绘制他的对应轨迹,这里选择James Harden,虽然我完全不看球赛,也不知道他是谁,我是根据原案例选的。对于背景图,可以自己用matplotlib绘制,一笔一笔的,非常困难。所以我们用一张上面Demo的底图,转化为PNG格式就行。这一工作主要是考察matplotlib.pyplot的操作能力。
harden = df[df[player_name] == James Harden] #选择James Harden这一行的数据
court = plt.imread("图像地址")
plt.figure(figsize = (15, 11.5))
plt.scatter(harden.x_loc, harden.y_loc, c = harden.game_clock, cmap = plt.cm.Blues, s = 1000, zorder = 1)
#用散点图绘制轨迹;cmap = plt.cm.Blues,用colormap来设置随着game_clock变动而发生的轨迹颜色变化,越接近结束时间颜色越淡。
#zorder = 0 设定Harden运动轨迹下的赛场线
cbar = plt.colorbar(orientation = horizontal) #图例横向摆放
cbar.ax.invert_xaxis()
plt.imshow(court, zorder = 0, extent = [0, 94, 50, 0])
#原图中的原点(0, 0)在左上角,所以我在本图中继续按照这个标准设置原点,(0, 94)为x轴的范围,(50, 0)为y轴的范围。
在第一部分Demo的演示中,13号Harden一度出界,所以需要扩展x轴的范围。
plt.xlim(0, 101)
plt.show()
Part 4. 欧几里得距离计算并绘图
根据连续点的坐标来计算Euclidean距离。
scipy.spatial.distance中可以直接计算欧氏距离,但是这里用numpy模块可以写出计算过程。
def travel_dist(player_loc):
diff = np.diff(player_loc, axis = 0)
dist = np.sqrt((diff ** 2).sum(axis = 1))
return dist.sum()
dist = travel_dist(harden[[x_loc, y_loc]])
#显然连续点需要传递坐标点的x,y值,而diff正是计算了前后两个点之间的距离。
可以用pandas中的groupby与apply来计算每一个运动员的移动距离。
player_travel_dist = df.groupby(player_name)[[x_loc, y_loc]].apply(travel_dist)
player_travel_dist
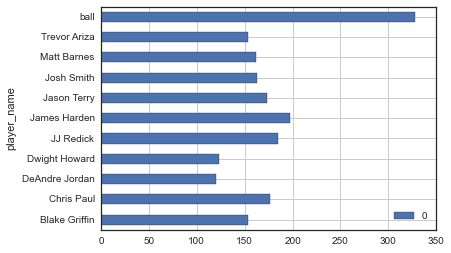
转化为数据框,并直接用pandas内置方法画图,由于距离可能会比较长,选择条形图应该比选择柱形图更适合展现。
df2 = pd.DataFrame(player_travel_dist)
df2.plot(kind = barh, style = g)
最后可以看出,除了篮球本身的移动距离外,James Harden的移动距离最长。
 写到这里,还有很多可以继续深入分析的内容。
写到这里,还有很多可以继续深入分析的内容。
作者:Lyndon
原创文章,作者:数据特工,如若转载,请注明出处:《Python:NBA运动员的运动轨迹呈现》http://www.afenxi.com/post/10351



