Wei Xiaowei, vice President of Baby Tree, the largest mother and baby community in China: Why is agile BI our inevitable choice?
Introduction: Baby Tree -- the largest mother and baby community in our country, has been growing so fast for several years, the reason of which is inseparable from its strategy attaching importance to data operation. Baby Tree is expecting that not only IT staffs but also overall employees know how to use the data. Wei Xiaowei, vice President of Baby Tree, believes that agile BI is the inevitable choice for Baby Trees. So why does Baby Tree make such a choice? What benefits does it bring to Baby Tree?
Q: Will you briefly introduce the data department of Baby Tree?
A: Our data team has been established three years ago to build IT infrastructure for us on the one hand, on the other hand, sort out our current data for structuring. Because when we talk about big data, we often mean structured data and unstructured data utilization rate is very low. Last year, we have upgraded this department to enclose some tasks such as algorithm of big data, some data upgrade applications including tools of internal data and implementation of App precision deployment tools, etc.,to this department which now has less than 30 employees.
Q: Is your company carrying out data analysis by yourself or working with a third party?
A: it's more about external assistance. Because data are the core of the company, especially business data. More work should be done by the third party. We have chosen to cooperate with Yonghong Tech, a domestic manufacturer of data visualized analysis, and built our own data analysis system on the basis of Yonghong Z - Suite. In my understanding, Yonghong BI actually has provided us with a system platform, and then we have depended on the requirements to make a secondary development on this platform.
Q: So, why did you choose this partner?
A: We did have data background system before but not agile enough, and we have decided to cooperate with Yonghong Tech because we were attracted by its agility. It is not enough for a group of data makers to use data, and we wish all corporate employees can operate it properly. Then, agility is a must. Secondly, I believe the data should be agile as long as the premise of accurate big data development capability. We have excluded other products by exclusive method and we believe Yonghong Z-Suite is the most suitable for our needs.
Q: What is the most obvious change brought to before and after using this product?
A: The work efficiency has been significantly improved. E.g., before, employees in any of our departments who required to run data had to work from 12 o 'clock at middle night till 7 o 'clock the next morning due to bigger server load, waiting for 24 hours. But now, we can solve this problem and operate it very well any time.
Q: How will you classify data?
A: Our own big data are roughly classified into three categories. The first category is called user base data, especially users' gender, age and pregnancy, which can make 70% of the portraits of users.
The second category is UGC data, because we ourselves are a community website where users leave large amount of messages or information, we can further understand their needs through semantic analysis of contents left by users. In fact, all of our requirements are just perfect previous basic data analysis, and the positioning would be more accurate by analysis of users amassed for a long time, i.e., accuracy is associated with the time, and it is not possible for a company to set up a system and finish data analysis within one day, because it depends on time. The longer the time, the better the users’ portraits.
The third category of data is known as browsing data. That is to say, in addition to the above tow categories that very precisely help to define 80%-90% of user need , while such analysis actually depends on quantity, e.g., in 3 consecutive days, if the user is browsing the discussion notes about powdered milk, he/she must plan to purchase milk powder, or wish to change a brand. By analyzing these three categories of data, we can basically define more than 90% of users.
Q: Do you feel any pressure for data processing?
A: We don’t have too much pressure with data processing now, as we all know, data have shelf life and will be expired, so that we regularly clear them every basically every three months after analyzing and sorting data, and we will store those relating to user management, because data generated three months ago are basically useless, e.g., the data relating to need of billions of users we accumulated in November are useless and out of date. We are less stressed because we fully understand refreshing time of the data as we define as three months. All data have a shelf life that is different for various industries.
Q: Do you involve user privacy when analyzing data?
A: for example, as to the phone number, home address and other privacy, the backstage technologists only very a few people have the right to see the data of personal privacy, operators can see the user behavior data in most cases.
Q: What does the data analysis bring to you?
A: We are now guiding product development by insight into customer needs. For example, we have found that the words of allergy and eczema were also mentioned in three months to six months later since people started to mention smog and air pollution. So we have predicted that in 2014, sales of milk powder preventing allergy or promoting intestinal digestion would increase,according to statistics in 2014, there were two brands sold very fast among the overall sales of milk powder, and their points of competition are to prevent children allergy. This is our advantage with user demand insights. In addition, every month, we pick up the top-listed user keywords, e.g., the word of progesterone that was listed behind No.two hundred in about three years ago has jumped into the top 10 since last year; after we made a survey, we have found that the pollution resulting in abnormal of progesterone, then we wondered if we could develop products to adjust abnormal progesterone. So we contacted the Chinese Academy of Sciences to see if we should develop a pregnant milk powder together according to this requirement.
To meet user demand, we would try out best if we could do ourselves, and we would look for partner if we couldn't do it.
Q: Are your data sources some so-called key user data?
A: for the time being, we only use our own data, but because SEO is doing well, many Baidu search terms are guided into our database. Except for this, we use ours.
Q: do you have roles like data scientists?
A: not exactly. One is algorithmic engineer who knows how to set up DC (data center), another, the second one, is algorithmic analyst, who should see what's behind the data. Furthermore, the one who actually makes it real is engineer who should have some data analysis base. So these three kinds of people are necessary. In addition, there should be someone to enjoy their results, e.g., those who are specialized in asking questions in addition to the setting of questions are very critical. The question should not be like “do you need fitness?”otherwise, it would be hundred percent failure to build a fitness center if every body’s answer was yes, therefore we should not dig the so-called customer insight through unscientific research and unreliable questions.
Q: What is your latest understanding of big data through these three years of development?
A: First of all, I believe there must be someone among the senior management who has relatively profound cognition to the big data, not only knowing the big data but also having commercial sensitivity, e.g., when the environmental pollution is more and more serious, what keywords were the most relevant to the keyword of environmental pollution, then the case of milk powder happened. We cannot catch opportunities by only studying data if not guided by senior management in all aspects. So that the big data analysis should be based on assumptions, and then to prove or refute some people's assumptions. And such assumptions need to change quickly. Any of our algorithm and model are not a molded in once time, because there are a few small details shall be adjusted according to the actual situation, in fact, the last algorithm version, we think, is reliable, which completely follows other direction when compared to the initial ones. Therefore, it's a very trivial thing that we actually build a team to adjust these things every day.
Q: Everyone is doing data analysis. What do you think is your biggest difference?
A: The degree of precision is different. Taking advertising as example, big data can convert traffic of the community into e-commerce sales, and the conversion rate is higher. After the background algorithm, the best CTR records now increases from 3 percent up to 5.5 percent. It should be a big data analysis that most people recognize. Baby Tree has now evolved to begin to carry out user insight through big data so as to guide advertising push and products. On the one hand, the advertising algorithm is precise so much that the user can see the advertisement at the right time when he/she just needs the product .
Taking loan AD for example, we have to introduce loan AD to ten people who just need the loan, which is known as precision marketing. We have achieved the rate of precision marketing up to 1.5% now, and the average rate is about 1% within industry. Another contribution of big data is to selection guidance, by which we can know clearly what users need. Take koro apparatus for example, as soon as we found mom after postpartum frequently mentioned the key word of koro, we have hastened to contact manufacturers and suddenly we have sold more than three thousand koro apparatus. The sales is very good.
Q: What is your current position on big data?
A: In my opinion, the big data are basically one of the most important products of Baby Trees, and it will be the driving force of Baby Trees to use big data in the next five years.
Q: Will you now provide relevant reports for the entire industry?
A: Yes, we can provide a small white paper every month and relatively bigger one every quarter, relating to air pollution, second child, festivals, etc, whose content can be used as an industry guidance.
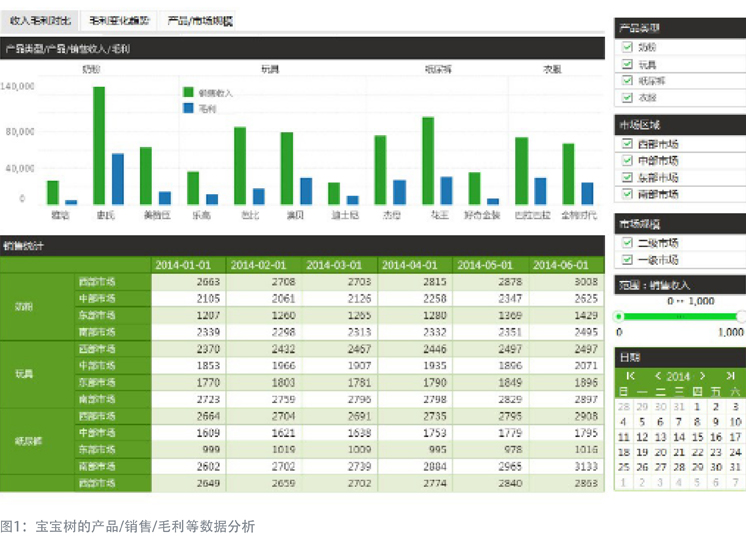
Figure 1: Data analysis of products/sales/gross profit, etc., for Baby Tree


